DeepSeek V4’s release is not just a technical iteration but a significant shift in the AI industry. With a 1.6T parameter MoE architecture, efficient handling of 1 million tokens, and MIT open-source licensing, this Chinese AI model is redefining industry standards with its disruptive technology and business logic. This article will comprehensively analyze how V4 rewrites the AI competitive landscape, from model architecture and training methods to geopolitical implications.

On April 24, DeepSeek launched V4 after a wait of nearly a year and a half. From the debut of R1 in January last year to the V4 preview going live, there was a 15-month gap with little news from DeepSeek, aside from a few minor updates. Rumors about V4’s arrival had circulated since January, but it wasn’t until April that it finally materialized.
I reviewed the technical report on the night of its release and spent a day running tests. This article presents my most honest assessment.
What Exactly is V4?
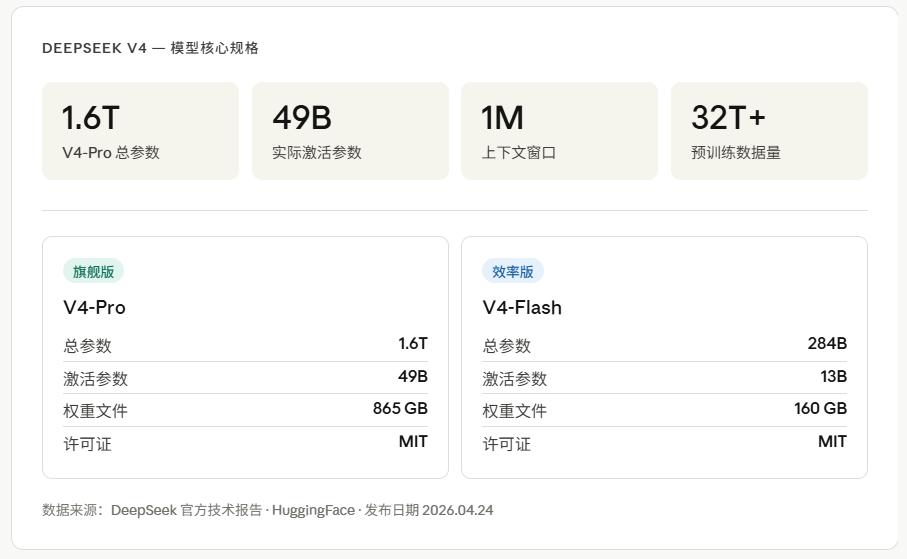
V4 has released two models: V4-Pro and V4-Flash. V4-Pro is the flagship model with 1.6T total parameters and activates 49B during inference, while V4-Flash is the efficiency version with 284B total parameters and activates 13B. Both support 1 million tokens of context and are available for download on Hugging Face under the MIT license.
A crucial number to understand is what 1.6T parameters and 49B activation mean. The core logic of the MoE architecture is that there are many “experts” in the model, but only a small portion is activated for each token processed. Thus, while V4-Pro has a total parameter count of 1.6T, the actual computational load is based on the 49B scale. This is why it can outperform dense models with the same parameter count in terms of efficiency.
To illustrate, it’s like a company with 1600 employees, but only 49 are needed to complete a task at any given time.
The weight file for V4-Pro on Hugging Face is 865GB, while V4-Flash is 160GB. If you have a MacBook with 128GB of RAM, the Flash version might run, but the Pro version would theoretically need to stream experts from disk, which wouldn’t provide a great experience.
Key Technological Breakthroughs
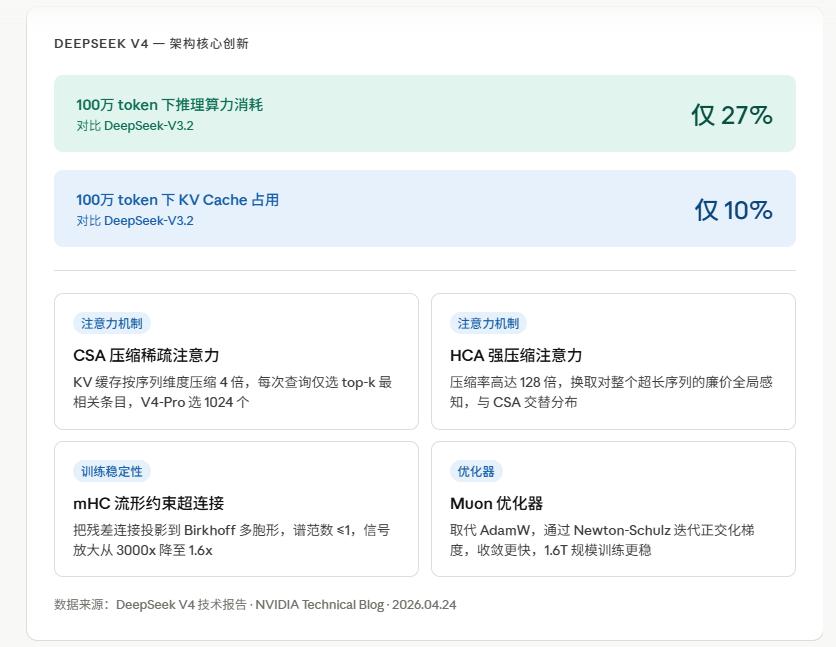
The most impressive aspect of V4 is not its parameter scale but how it addresses the efficiency of handling long contexts. While 1 million tokens of context is not a new feature (Gemini has supported it for a while, and Claude has been working on long contexts), there is a significant challenge known as the quadratic complexity of the attention mechanism. As context length increases, computational load grows quadratically, not linearly. This means that expanding context from 100,000 to 1 million tokens theoretically increases the computational load by 100 times.
Thus, most companies’ million-token contexts are a “usable but expensive” feature, leading to skyrocketing bills when used at scale. DeepSeek V4 tackles this issue at the architectural level.
They employ a mixed attention mechanism that intertwines two new types of attention:
First Type: CSA (Compressed Sparse Attention)
Traditional attention requires each token to compute relevance with all other tokens in the sequence. CSA compresses the KV cache along the sequence dimension, achieving a compression rate of 4 times, and uses an “indexer” to select the top-k most relevant compressed entries for each query. V4-Pro selects 1024 entries each time, while V4-Flash selects 512, maintaining a sliding window of 128 tokens to ensure local context is not overlooked.
Second Type: HCA (Highly Compressed Attention)
While CSA is a refined process, HCA is a more aggressive compression method, achieving a 128-fold compression rate by merging many tokens into a single entry and applying dense attention on this highly compressed representation. This allows the model to gain a global perspective of the entire long sequence with minimal computational cost.
CSA and HCA are alternately distributed across different layers of the model. V4-Pro starts with the HCA layer, while V4-Flash uses a sliding window in the first two layers and then alternates. This allows the model to dynamically switch between “precise sparse lookup” and “coarse global perspective” at each layer, rather than being limited to one or the other.
As a result, under 1 million tokens of context, V4-Pro’s single-token inference computational cost is only 27% of V3.2’s, and KV Cache usage is only 10%.
With the same context length, computational load has dropped to 27%, and memory usage to 10%.
This is not a minor optimization; it’s a dimensionality reduction at the architectural level. This means that 1 million tokens of context on V4 becomes a financially viable everyday feature, rather than a premium feature only accessible to wealthy clients.
Another architectural innovation is called mHC (Manifold-Constrained Hyperconnection).
This addresses training stability. In standard Transformers, residual connections add the layer’s input directly to its output, which works fine in shallow networks but can lead to instability in very deep models, causing signal amplification, oscillation, and training crashes.
mHC projects the residual connection onto a mathematical manifold called the Birkhoff polytope, using the Sinkhorn-Knopp algorithm to enforce the double stochastic matrix constraint, limiting the spectral norm to ≤1.
In simpler terms, without mHC, DeepSeek’s own 27B experiments experienced a 3000-fold signal amplification that caused training to crash. With mHC, the amplification was reduced to 1.6 times, allowing stable training at the 1.6T parameter scale.
This innovation has been recognized by IBM, Fireworks AI, and several research teams as a foundational contribution to the stability of deep network training, potentially impacting more than just attention mechanisms.
Finally, the Muon Optimizer
Traditionally, large models have been trained using AdamW, but DeepSeek V4 has switched to Muon. The core principle of Muon is to orthogonalize the gradient update matrix using a Newton-Schulz iteration approximation before applying it for weight updates. The practical effect is faster convergence and more stable training, which is crucial at the 1.6T scale, where the optimizer’s stability can mean the difference between catastrophic failure and normal training.
Thus, V4’s architecture is not just a “bigger V3”; it represents substantial restructuring across attention, residual connections, and optimizers.
Notable Changes in Training Methods
V4’s post-training pipeline differs from previous versions.
It employs a two-phase method: first, separate training for experts, and then integration.
In the first phase, individual expert models are trained for each specialized domain, such as mathematics, coding, agent tasks, and general instruction. Each expert undergoes SFT fine-tuning, followed by RL training using GRPO (a reinforcement learning technique previously used in R1) under domain-specific reward models, allowing each expert to reach its limits in its field.
In the second phase, OPD (On-Policy Distillation) integrates the capabilities of all experts into a unified model.
OPD differs fundamentally from standard distillation; in standard distillation, the student directly mimics the teacher’s output, while OPD has the student generate answers first, which are then evaluated and corrected by 10 expert teachers, allowing the student to learn from this feedback.
What are the benefits of this process?
Traditional multi-capability joint training suffers from a notorious issue known as knowledge interference, where the logical rigor of mathematics clashes with the flexibility of creative writing, and the deterministic thinking of coding compromises general reasoning. The result is a model that performs adequately across the board but lacks excellence in any specific area.
V4’s two-phase approach allows each capability to reach its ceiling before integration. Benchmark results indicate that this approach is effective.
However, there is a caveat: DeepSeek acknowledges in the technical report that V4 used outputs from 10 teacher models for OPD. OpenAI and Anthropic have publicly accused Chinese AI companies, including DeepSeek, of illegally distilling capabilities from models like Claude through 24,000 fraudulent accounts, running 16 million dialogues. The U.S. White House issued a memorandum the day before V4’s release (April 23), stating that “industrial-scale” capability theft poses a national security threat.
DeepSeek has not directly responded to this accusation, while the Chinese Foreign Ministry termed it a “slander against China’s AI achievements.”
This line of inquiry remains unresolved but will be an unavoidable shadow over V4’s lifecycle.
What Do the Benchmarks Indicate?
Let’s present the numbers.
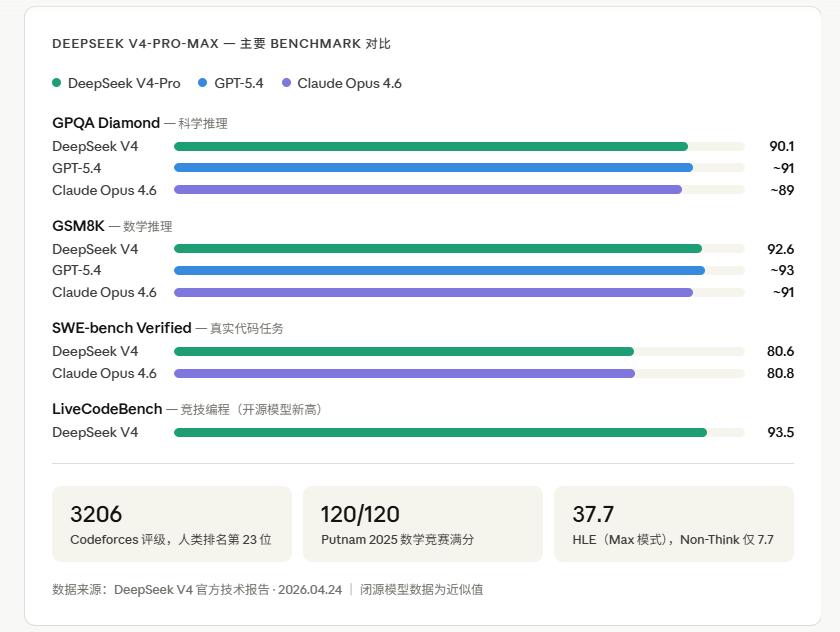
V4-Pro-Max’s scores include GPQA Diamond 90.1, GSM8K 92.6, MMLU Pro 87.5, LiveCodeBench 93.5 (the highest score for any new open-source model), and a Codeforces rating of 3206 (ranking 23rd among human competitors).
Compared to closed-source models, V4 holds its own against Claude Opus 4.6 and GPT-5.4 in programming benchmarks, achieving 80.6% on SWE-bench Verified, just 0.2 points behind Claude Opus 4.6.
While these numbers look impressive, there are several points to consider:
First, the “V4-Pro-Max” mode reflects results under maximum inference budget, not typical usage conditions.
V4 offers three inference modes: Non-Think, Think High, and Think Max. For the same model, the HLE (high-level difficulty benchmark) shows scores of 7.7 in Non-Think mode and 37.7 in Max mode, a nearly fivefold difference.
The benchmark numbers presented are from Max mode; the actual API call costs and speeds will vary significantly, making them not directly comparable.
Second, there are still gaps in knowledge-based tasks.
DeepSeek’s technical report admits that V4 “lags behind the most advanced frontier models by about three to six months.” In knowledge-intensive benchmarks, V4-Pro-Max still trails Gemini 3.1 Pro. Tasks like MMLU-Pro, SimpleQA, GPQA Diamond, and HLE represent a broad accumulation of world knowledge, where larger parameter counts tend to show more advantage, and Gemini currently outperforms V4.
Third, the retrieval quality for ultra-long contexts has its limits.
The theoretical appeal of 1 million tokens is undermined in MRCR tests, where retrieval accuracy begins to decline after exceeding 128K tokens, dropping to only 66% at 1 million tokens. While this is not unusable, it falls short of “perfect handling of 1 million tokens.” It may be suitable for understanding entire codebases, but caution is advised for precise legal document retrieval.
Fourth, the gap between V4-Pro and V4-Flash is smaller than expected.
Under the same inference budget, Flash-Max’s performance on inference benchmarks is very close to Pro-Max, with only a 1 to 2 point difference, yet the API cost is 1/12th that of Pro. If your business does not require extensive knowledge breadth, Flash-Max may be the most cost-effective choice.
Pricing Strategy
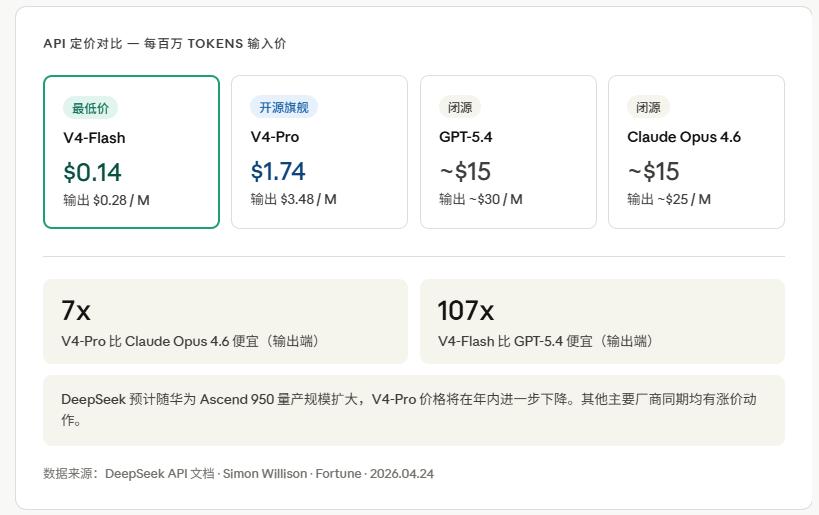
In this section, I find myself at a loss for words, as DeepSeek’s pricing logic cannot even be described as “cheap”; it’s practically giving it away.
V4-Flash has an input price of $0.14 per million tokens and an output price of $0.28 per million tokens.
V4-Pro has an input price of $1.74 per million tokens and an output price of $3.48 per million tokens.
For comparison, GPT-5.4 and Claude Opus 4.6 charge $25 to $30 per million tokens for output.
V4-Pro is priced at $3.48.
For equivalent programming benchmark performance, V4-Pro is over 7 times cheaper than Claude Opus 4.6.
V4-Flash is even cheaper than GPT-5.4 Nano, making it the lowest-priced small frontier model currently available.
Another impressive detail is that DeepSeek stated that once the Huawei Ascend 950 processor scales up production this year, V4-Pro’s prices will further decrease.
What does this imply?
It means that while other companies are contemplating how to raise prices for high-quality APIs, DeepSeek is focused on how to continue lowering them. Their business logic operates on an entirely different level.
Of course, the extremely low price comes at a cost. DeepSeek heavily relies on domestic chip infrastructure to control costs, and this path is viable only if Huawei’s computational capacity can indeed scale up effectively.
The Geopolitical Context
The release of V4 is significantly influenced by Huawei’s chips. Bloomberg reported on April 26 that the release of V4 was delayed for several months because DeepSeek spent time restructuring its underlying software stack. The goal was not just to ensure the model could run on Huawei Ascend chips but to achieve hardware-level optimization, specifically targeting memory access and operator arrangement.
Huawei confirmed on the day of V4’s release that their AI clusters can support V4’s operation. The stock price of Semiconductor Manufacturing International Corporation (SMIC) rose by 10% that day, as SMIC is one of the manufacturers of Huawei’s Ascend processors.
The implications of this signal extend far beyond AI itself. If DeepSeek can indeed train and run a cutting-edge large model without Nvidia’s most advanced chips, it disrupts the entire logic chain of U.S. chip embargoes and the constraints on China’s AI development.
However, many questions remain unanswered. How much of the training utilized Huawei chips, and how does it compare to Nvidia’s? What is the actual performance of the Huawei Ascend 950PR’s claimed 2.87 times H20 performance in large-scale training? DeepSeek has not disclosed this data, and independent verification based on chip consumption has not been released.
But the direction is clear: China is consciously building a parallel AI infrastructure, with DeepSeek as a key model supplier. This development is more significant than any benchmark score.
Limitations Acknowledged by the Technical Report
Notably, DeepSeek’s technical report candidly addresses the limitations of V4 without excessive hype.
The first issue is that the architecture is too complex. To manage risks, V4 retains many components already validated in V3 while incorporating new innovations like CSA, HCA, mHC, Muon, and FP4. The technical report states that the current architecture is relatively complex, and the next generation will aim to simplify it to its essential design. In other words, V4 resembles a modified vehicle that has become heavier due to the addition of various new features, lacking elegance.
The second issue is that the principles behind training stability have not been fully understood. They implemented two new techniques to address training instability, Anticipatory Routing and SwiGLU Clamping, which are effective in practice, but the technical report admits that “the underlying principles are not fully understood,” calling training stability a “fundamental issue to be studied.” While it has been addressed from an engineering perspective, the academic explanation is still lacking.
The third issue is the lack of multimodal capabilities. This is the most apparent gap. GPT-5.4, Gemini 3.1, and Claude Opus 4.6 all deeply support multimodal inputs like images and videos, while V4 remains purely text-based. DeepSeek claims to be “actively developing” multimodal capabilities, but the current version does not support them. Reports suggest that the multimodal feature was delayed due to computational and funding pressures, and DeepSeek had just opened an external financing window in mid-April, making the timing noteworthy.
DeepSeek has previously conducted extensive research related to visual language models, including DeepSeek OCR, so the technology reserve for multimodal capabilities exists; it is a matter of prioritization. However, this means that if your business requires processing images or videos, V4 cannot assist.
The fourth issue is that V4 does not have a new narrative like R1. The breakout of R1 in January 2025 was due to its revolutionary concept: achieving top-tier inference capabilities with minimal investment and limited chips. This story fundamentally rewrote the underlying logic of the AI industry, leaving everyone stunned.
What is V4’s story? Bigger, cheaper, longer context, and more elegant architecture. While these are all true, it continues to evolve within an already established cognitive framework without breaking new ground.
Morningstar analyst Ivan Su stated, “The market has already digested the conclusion that ‘Chinese AI is both competitive and cheap.’ The release of V4 will not trigger a shockwave like R1 did.”
V4’s Position in the Industry
To developers and enterprise users, V4-Flash is currently the most cost-effective frontier small model available.
With 13B active parameters, 1 million tokens of context, and Max mode inference capabilities close to Pro, it costs only $0.28 per million tokens. For businesses requiring extensive API calls for code generation, document processing, or agent workflows, Flash is the top choice.
V4-Pro is optimized for mainstream agent frameworks like Claude Code and OpenClaw, achieving state-of-the-art performance in the Agentic Coding benchmark. If you are building a heavy code agent, it is worth testing Pro as a replacement.
Regarding industry competition, V4 has changed the competitive framework in China’s open-source AI sector. During the R1 era, DeepSeek was a challenger, competing against closed-source models like GPT and Claude. In the V4 era, DeepSeek has begun to position domestic competitors such as Alibaba’s Qwen, ByteDance’s Seed, MiniMax, and Moonshot as direct rivals—this shift indicates that domestic AI competition has entered a heated phase.
On the day of V4’s release, the stock prices of MiniMax and Zhipu (Zhihu) dropped by about 8%, and Manycore Tech fell by 9%. The capital market’s response was direct.
Finally, from a geopolitical perspective, this release represents a demonstration of AI sovereignty. Regardless of how V4’s technical details are interpreted, one core signal is undeniable: if the Huawei chip route proves viable and this cost structure is sustainable, China will have a set of cutting-edge AI infrastructure capable of operating independently of U.S. export controls.
This fundamentally alters the competitive landscape beyond any benchmark score. V4 marks DeepSeek’s significant return to the forefront of AI. With solid technology, innovative architecture, aggressive pricing, and a commitment to maintaining an open-source ecosystem, it has secured its position as the leader in the open-source arena.
However, it is not a disruptor but a defender. It has solidified its position as the leader in the open-source space but does not aim to shock the industry as R1 did.
Three intriguing questions remain regarding V4:
- When will the multimodal version arrive, and will it be able to compete with Gemini and GPT-5 in image and video processing?
- How far can training efficiency and pricing drop once the Huawei Ascend chips scale up production?
- What strategies will domestic competitors like Qwen, ByteDance, MiniMax, and Zhipu employ in response to V4?
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.